
Findings from Chakraborty (2021) Reproduction
Introduction
The second project that I worked on in Open Source GIScience was a reproduction of the 2021 paper Social inequities in the distribution of COVID-19: An intra-categorical analysis of people with disabilities in the U.S. The process of reproducing this study was definitely more difficult, but also more informative than the Alabama Gerrymandering Case Study. This is because of how in-depth this reproduction challenged me to go in terms of data transformations and analysis in R, as well as in my intentional use of the research compendium.
Because this reproduction was adapted from a prior reproduction, the scope of this project for me was more of a partial or parallel reproduction of the original paper.
Findings from analysis
The methods from this study, especially the cluster analysis, were more complicated, and I felt less empowered to be able to understand it by myself. My repository/research compendium contains all of the different steps in understanding the workflow of the original paper. This begins with my workflow chart which I drew up after reading through Chakraborty’s paper. Next, is the collaborative class discussion workflow, which was a very valuable experience for me, as I got to hear from my peers who had more spatial analysis and R experience than I do. Finally, my pre-analysis plan details roughly the steps that I planned to impliment, with the help of the prior reproduction’s code.
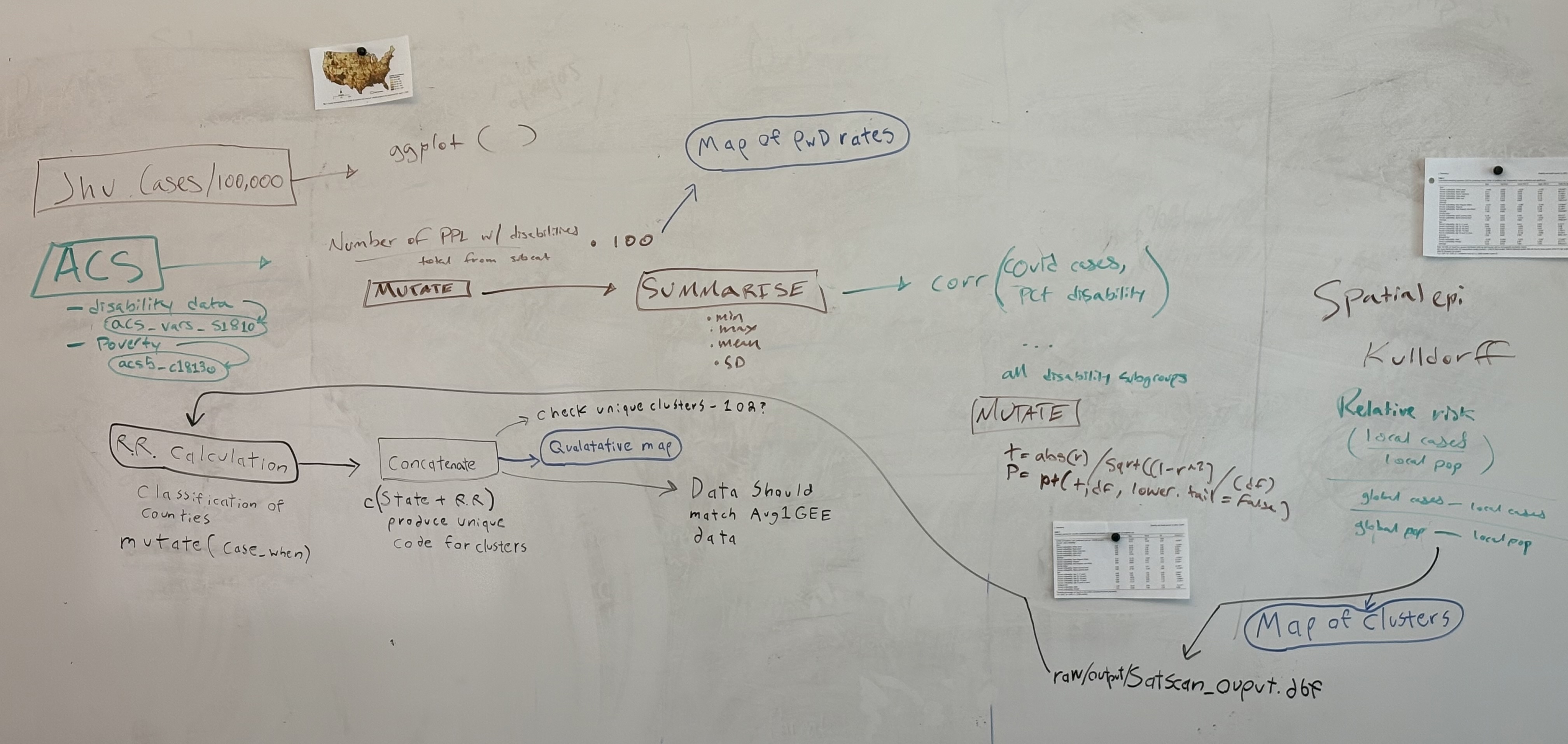{kind=link}
It was a little bit of a struggle to understand all of the findings from the reproduction, however, the reproduction code was essentially able to reproduce Table 1 and Figure 1, while SpatialEpi in R reported more clusters than the original study. Also, as touched upon in the discussion section, some counties were found to have incorrect COVID incidence scores, which resulted in inaccurate correlation coefficients.
Reproducibility practice takeaways/points for improvement
Despite the hurdles of making sense of the methods in the prior reproduction’s code, I found this project to be a lot more useful (especially in the struggle of working through it) as an exercise in Open Science. Because it was a reproduction project, I was able to experience how to approach interpreting an author’s workflow, (again) making a pre-analysis plan, and then implimenting it. To me, this project felt far more focused on the practice of reproducibility than the actual details of the analysis, especially since the paper had been reproduced before. I felt confident in my work initially interpreting the study workflow, but in the end, I needed to rely heavily on the code from Prof. Holler and the other prior reproduction authors. I feel that the practice of reproducing this study was an overall success, because we made the workflow and transformations more clear, and we produced maps visualizing important elements of the study (like the clusters) that the original paper did not. I definitely learned a lot, and I felt much more familiar with using the research compendium template after this project!